
Creating a robust AI model for object detection and/or classification in images and videos is a multi-step process. This guide will outline the key steps to develop a high-performing model capable of accurately identifying and categorizing objects.
#1. Prepare a dataset
We have already discussed how to create a good dataset here.
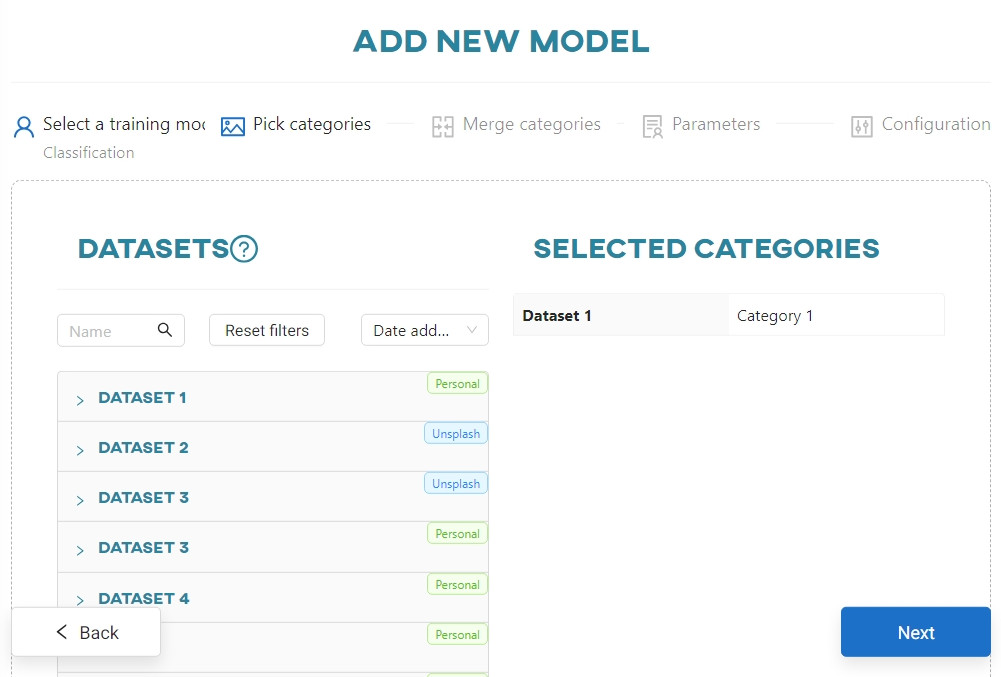
#2. Select categories
Select the categories of objects you want to detect or classify. Make sure that each selected category has a roughly similar number of images. For classification you need hundreds of images, while for object detection you need thousands.
#4. Choose a framework
A framework refers to the underlying software ecosystem or library that provides the necessary tools, functions, and infrastructure for building, training, and deploying AI models. OneStepAI has two frameworks for detection:
And two frameworks for classification:
-
TensorFlow 2.5.1 - read the official documentation here
-
PyTorch 1.8.1 - read the official documentation here
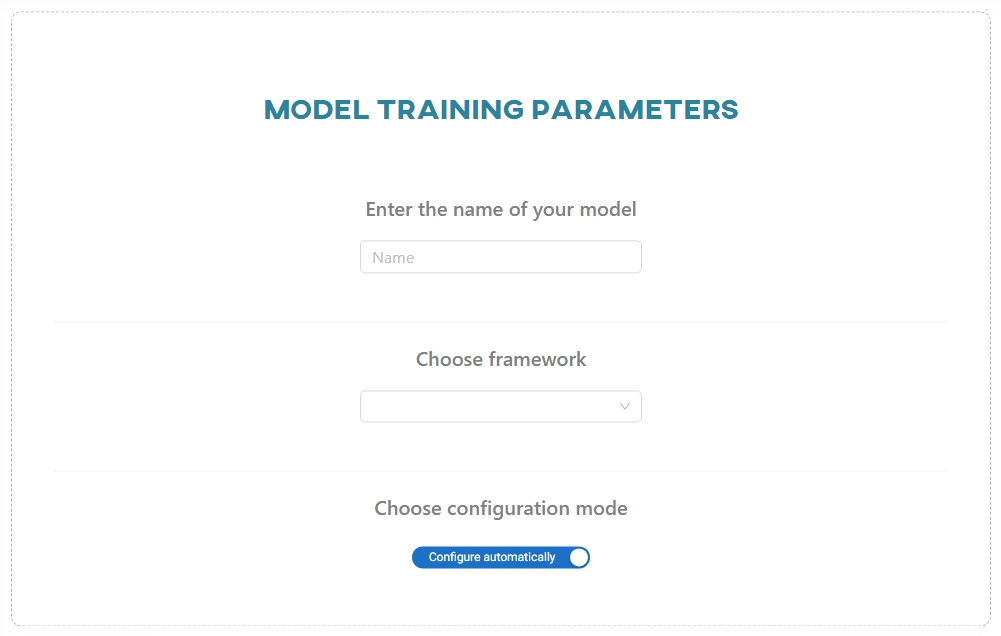
#5. Parametrization
Select the appropriate parametrization method based on your knowledge and requirements. There are two options available: Configure automatically and Configure manually. The first option automatically adjusts settings for an optimal training process and is recommended for individuals with limited knowledge of AI. The second option allows you to adjust the settings yourself and is recommended for those with AI expertise.
Keep in mind: Modifying parameters may lead to a decrease in model performance; however, conversely, the default parameters may not be optimal for a given model.
#6. Basic parameters
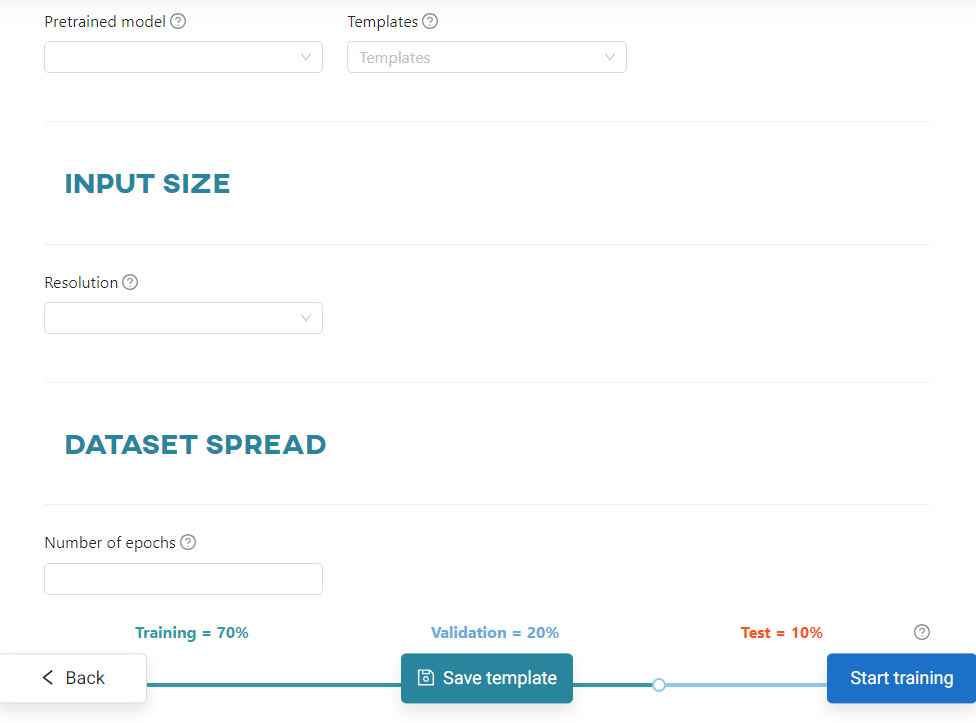
Pretrained model - a machine learning model that has been previously trained on a large dataset. It has learned to extract features or patterns from the input data and can make predictions or perform tasks related to that specific domain. Each pretrained model is described here.
Input size - refers to the dimensions of the data, often used for images, that the model expects for processing. A larger size may lead to slower training of the model.
Dataset spread - involves parameters such as max batches, batch size, subdivisions, burn-in, number of iterations, and number of epochs. These parameters collectively determine how the dataset is distributed and processed during training, affecting factors like computational efficiency, model convergence, and overall training performance. Adjusting these parameters allows fine-tuning the training process to balance computational resources and model accuracy.
The percentage division of the set of training images into three disjoint subsets involves using the Training subset to train the model, and the Validation subset to calculate its temporary accuracy. At the end of the process, the Test subset is used to provide the final accuracy of the model. The default split is 70/20/10.
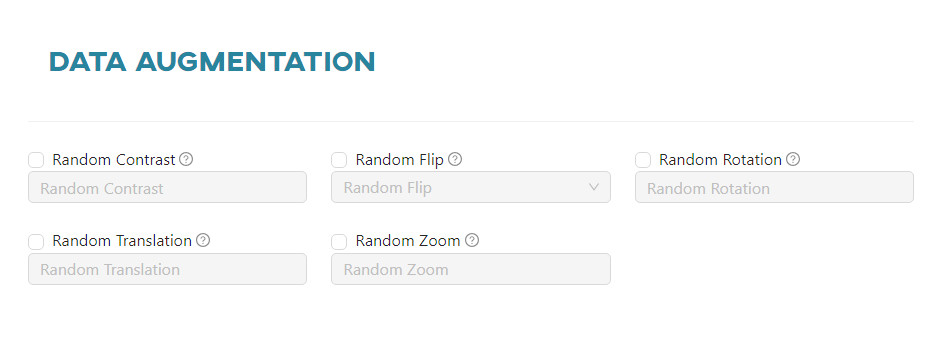
Data augmentation - applies various transformations to the original training data. Compared to the dataset manipulator data augmentation is an automatic process built into the framework, but its results are not visible to the user and it provides less control over them than in the manipulator. Each data augmentation is described in the Creating a model article.
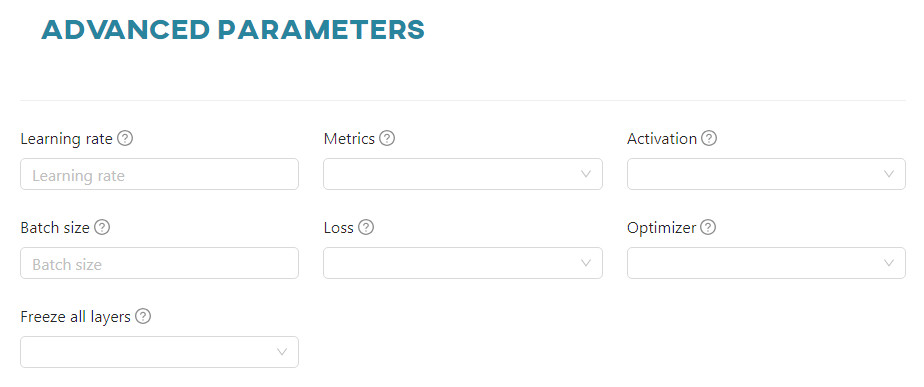
#7. Advanced parameters
Each framework has different advanced parameters, such as learning rate, activation, batch Size, loss, optimizer, freeze all layers, metrics, momentum, decay, resize, and jitter. These play a key role in tuning and optimizing machine learning models. They govern aspects such as model convergence, adaptability and performance evaluation, requiring careful adjustment for optimal results. Each parameter is described in detail in the article Creating a model.
#8. Training the model
Once you have selected your parametrization method and configured the settings, initiate the training process. It is crucial to closely monitor the training progress and make adjustments as needed. Pay special attention to potential overfitting, where the model performs exceptionally well on the training data but may struggle with new, unseen data. Overfitting can hinder the model's generalization capabilities.
Keep in mind: Clicking the Stop option icon allows you to stop training in one of two ways:
Stop immediately, which terminates the process immediately and deletes the entire training, andStop with progress, which stops the process as soon as the current iteration (epoch) ends. The model and the result achieved so far will be saved.
#9. Read the results
The effectiveness of the training can be evaluated when it is stopped. To learn how to read the results, read the article Tracking model performance.
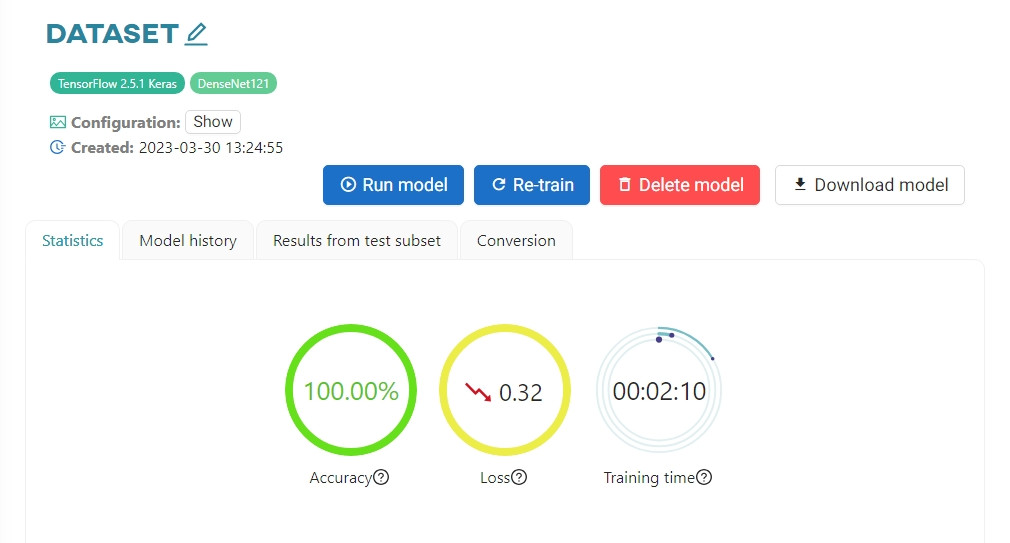
Keep in mind: Accuracy and loss are not the only indicators to consider, as they can sometimes be misleading. They do not solely determine the overall quality of the model.
#Conclusion
Building a reliable AI model for object detection and classification is a complex but rewarding process. By following these steps, you can develop a model that meets your accuracy and efficiency goals. Remember that AI model development is an iterative process, and continuous improvement is key to maintaining its effectiveness over time.